Participatory Data Science Update
Artificial intelligence, machine learning, and data science – these terms and technologies are proliferating wildly throughout our day-to-day lives, lately. And in many cases, these tools can harm people who are already at a disadvantage. What better time, then, for Community and Citizen Science to intervene, open up these black boxes, and put the tools in the hands of the people who would be most impacted by them? This summer, the Center for Community and Citizen Science tested out a method I’ve been developing to explore the potential for implementing data science best practices – including participatory approaches. My colleagues gave me great advice in thinking about who the audiences for the exercise are and how I envision them using them. I’m curious who else might be interested – so if this topic intrigues you, read on!
Public participation in modeling and data science is a key part of a set of best practices I developed several years ago: my Modeler’s Manifesto. I consulted my social science colleagues and the literature they recommended, in order to develop a set of practices that could make my modeling better, and the resulting Manifesto includes a range of ideas, including community-based modeling as well as better practices around transparency. I combined what I found with what other modelers and data scientists were saying on the same topics: how to make analyses more relevant, more trustworthy, and more just. I wrote a detailed description of each practice in a journal article in Research Ideas and Outcomes. I quickly found it easier to think about how useful these practices are by applying them to my actual modeling experiences, which I reported on in another article in Environmental Modelling and Software. I found that, to the degree that I applied the practices, I felt that I’d done a better job of making my modeling more just, trustworthy, and relevant. But how much of that was me, evaluating my own ideas against my own experiences?
So, along with various collaborators, I developed an exercise in which a modeler or data scientist thinks about a particular project, and then rates how feasible and impactful each of the proposed Manifesto practices would be if they could apply them to their project. By feasible, I mean how practical it would be to implement the practice; and by impactful, I mean whether it would be worth doing it. We’ve used Mural boards to make the activity both interactive and collective – describing the practices to participants, giving them time to place each practice as a digital “sticky note” on the axes of impact and feasibility, and then discussing the results. Some questions have revolved around how individuals made choices about where to place practices, how they defined feasibility and impact, and how their ratings might have depended on the project they chose to consider. Other questions focused on the collective nature of the exercise: where were there clusters of different practices? Where did people agree on the feasibility and impact of the practice for their project? Where were there differences?
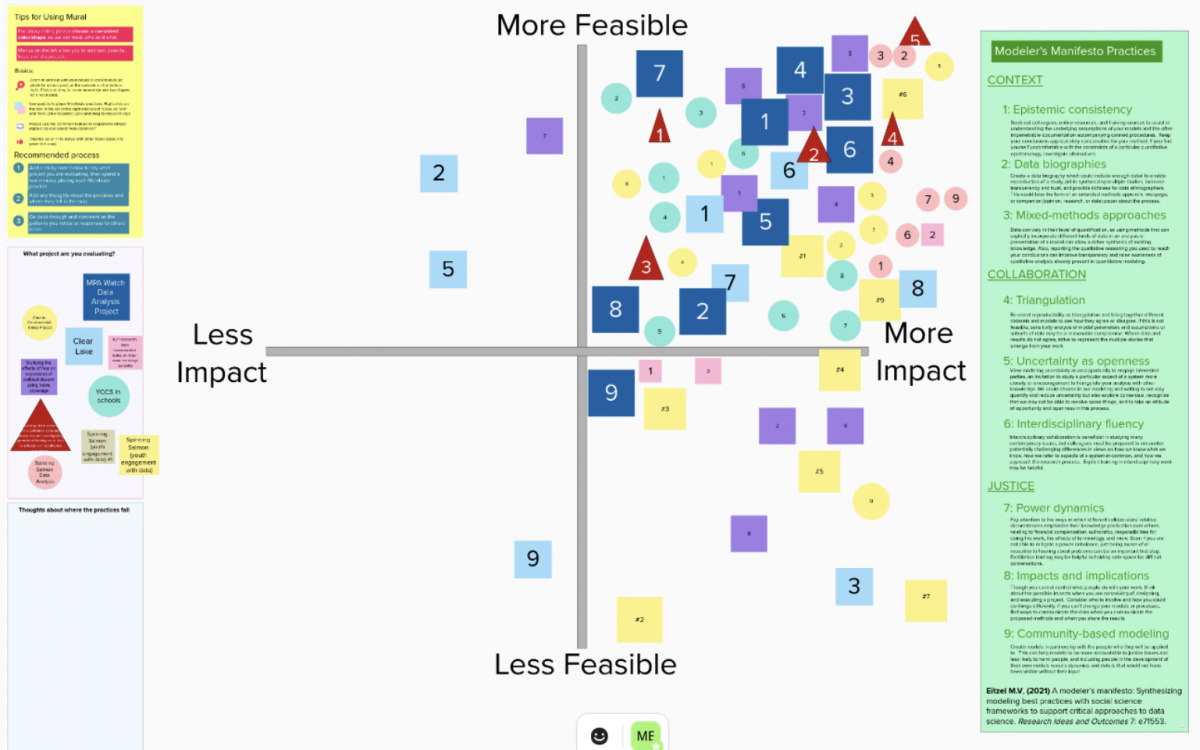
In addition to getting feedback from my colleagues at the Center, I’ve done this exercise with communities of practice like the Data Science by Design Collective and the UC’s Data Feminism book club, as well as students in data science and ethics classes in the UC Davis Feminist Research Institute’s “Asking Different Questions” graduate course, the UC Berkeley School of Information’s “Behind the Data: Humans and Values” graduate course, and UC Davis DataLab’s “Adventures in Data Science: Research in Data Studies” undergraduate course. We’ve had interesting discussions about how people in different roles and stages of their careers think about the feasibility and impact of these potential modeling practices. This summer, with the help of UC Berkeley CITRIS interns Iman Qureshi Tiffany Hoang, I developed a survey version for participants to fill out before the live session – both to investigate whether the responses differ when participants do the ratings solo versus in the collective environment, and as a potential alternative way to jumpstart group discussion, by getting feedback offline and then spending the majority of the time during the collective session discussing the way folks mapped the practices. I continue to ask participants questions like “what would make a practice more feasible or more impactful for your project, or in general?”
I’m hoping to take this project in two directions. First, I want to analyze the existing results of the exercises we’ve done so far. Who tends to rate which practices in what ways? What practices are consistently considered more feasible and/or impactful? When there are differences in ratings for a practice, why do we think they differ from person to person and project to project? And second, I want to expand the set of folks who have tried it. I’m interested in how folks in industry would find the exercise and how they would rate the practices – what is feasible in a software development firm is likely to differ wildly from what is feasible in an academic context. In addition to all that, many different groups could benefit from the thought experiment that this exercise provides. It could be useful to do the exercise at the beginning of a project, and then periodically throughout the project, as a more concrete form of ‘ethical science and technology development’ – though there are calls for this kind of shift, having specific ways to achieve it could be valuable.
If you are interested in doing the exercise or know a group who might be interested, please reach out to me at mveitzel.org!







